Introduction
For the past two years, the dominant frame for AI in research has been “LLM as a better search engine.” You ask a question, you get a summary, you decide what to do with it. Useful, but fundamentally passive.
That frame is starting to break. What I’ve been watching — and experimenting with in my own research — looks different. Instead of answering questions, these systems run workflows. They plan, call tools, hit dead ends, recover, and produce something you can actually use.
This post is about that shift: what the labs are building, what the current capabilities and limits actually are, and two concrete examples from my own work where the agent framing stopped feeling theoretical.
What the labs are building
The deep research pattern
OpenAI, Google, and Anthropic have all shipped something called “deep research.” The branding differs, but the architecture has converged on the same pattern:
- A planner breaks the question into a multi-step research plan
- Tool-using workers execute the steps — browsing, code execution, document retrieval
- A synthesizer produces a written report with citations
- Verification loops check correctness, flag contradictions, reduce hallucinations
These are not one-shot answers. A typical deep research run involves dozens or hundreds of model calls, tool invocations, and course corrections before producing output.
What actually makes this possible
LangChain’s Harrison Chase distilled what serious deep agents — Manus, Anthropic’s multi-agent researcher, Claude Code, open-deep-research — have in common (Deep Agents). Four things:
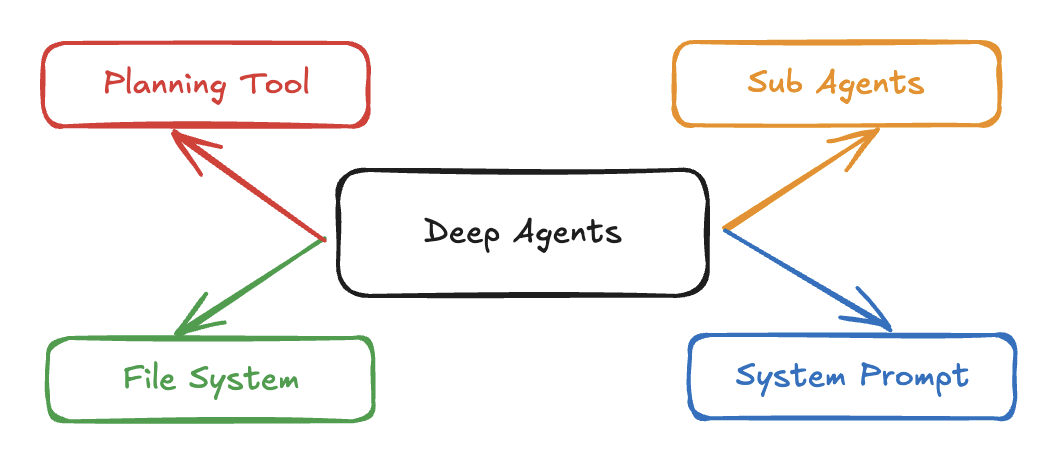
Planning externalised to a file. The agent writes a todo.md at the start, updates it as work progresses, and a human can inspect or correct it at any point. If the plan lives only in context, it degrades as the window fills. On disk, it persists.
Intermediate work offloaded to the filesystem. Retrieved documents, summaries, partial results — written as files, read back when needed. This decouples task size from context size. The filesystem is external memory.
Sub-agents for parallelisation and context isolation. An orchestrator delegates sub-tasks to fresh agents — each starts clean, does a bounded piece of work, writes output to disk, and exits.
The system prompt. More load-bearing than it looks. In every serious deep agent, the system prompt encodes the agent’s model of its environment: what tools exist, what the filesystem looks like, what counts as done. Model capability is table stakes; the system prompt is what makes it behave correctly in a specific context.
These four are what let a research agent operate over hours without losing coherence — and what makes it auditable. Beyond literature synthesis, coding agents and computer-use (OpenAI’s Operator, Anthropic’s computer use) matter for research because a lot of computational work lives in GUI environments, HPC terminals, and analysis scripts.
Scientific discovery systems
A related but distinct category: systems where the LLM is paired with a formal evaluator. FunSearch pairs an LLM with automated scoring and runs an evolutionary loop. Coscientist connects an LLM to cloud lab automation. The AI Scientist attempts the full stack: idea generation, coding, experimentation, manuscript drafting.
The lesson is consistent: the bottleneck is not only the model. It’s the evaluator. If you can build something that reliably scores outputs, the agent can search the space. If you can’t, you get a polished generator of plausible-looking nonsense.
What these systems can and can’t do
Strong performance on tasks that are textual, auditable, and decomposable into tool-checkable steps: literature mapping, code prototyping, document retrieval and reference management.
The benchmarks reflect this. GAIA tests real-world tasks requiring browsing, multimodality, and tool use — a better proxy for actual research utility than classic NLP benchmarks. DeepSearchQA targets specific failure modes: premature stopping, poor recall/precision balance, over-confidence on partial evidence.
The honest limits:
- Long-horizon planning is brittle. Complex multi-day investigations still need human checkpoints.
- Citation correctness isn’t guaranteed. Plausible-looking references that don’t actually support the claim remain a real failure mode.
- Prompt injection from untrusted sources is a live attack surface.
- Physical reality still forces a reckoning. A prediction pipeline can be automated; experimental validation cannot.
Example 1: Knowledge organisation and literature search
How my workflow evolved
When I started my PhD, I read papers and took notes in isolation. Each paper lived in its own document. Finding connections between them required me to remember they existed. Either using handwritten notes or using mind maps.
Then I moved to Obsidian — reading papers, using LLMs to help understand specific topics, summarizing into notes with backlinks. But it was still using LLMs as chat completion tools, and the bookkeeping was on me. Organizing topics, creating backlinks, keeping the structure coherent — a lot of time spent on the vault itself rather than on research.
Now I ingest papers into the vault using what Andrej Karpathy calls the LLM-wiki pattern — and the key distinction from standard RAG is worth quoting directly:
In RAG, the LLM rediscovers knowledge from scratch on every question. Nothing is built up. In the wiki pattern, knowledge is compiled once and kept current — cross-references are already there, contradictions have already been flagged, synthesis already reflects everything you’ve read.
Obsidian is the knowledge base. Claude Code (CLI) is the agent. The difference matters: the agent has direct file-system access, runs shell commands, and loads the vault schema automatically at session start. It operates inside the vault rather than being handed excerpts from it.
What the setup looks like
Three layers:
Raw sources — immutable PDFs and clipped articles in a raw/ folder. The agent reads here but never writes. Source of truth.
The wiki — maintained notes: a summary page per ingested paper, concept and entity pages, project status files. The agent writes these during ingest; I read them and ask questions.
The schema — a CLAUDE.md file at the vault root that describes the folder structure, conventions, and ingest workflow. Without it, the agent is a generic chatbot. With it, it’s a disciplined wiki maintainer.
For search I use qmd — a local hybrid search engine combining BM25 keyword matching, semantic vector search, and LLM reranking. Local because the notes are private; hybrid because local embedding models are weaker than cloud models and combining approaches closes most of that gap.
What actually changed
The shift isn’t that papers get read faster. It’s that knowledge compounds. A new paper gets linked to every concept page it touches, contradictions with prior notes get flagged, and the summary lands in the project index automatically. The vault gets denser and more connected over time — not just a folder of isolated PDFs.
Literature search went from “what do I remember about this?” to “what does the vault already know, and what’s still missing?”
My role went from bookkeeping to asking the right questions. I’m the orchestrator now.
Example 2: Running a simulation workflow
This is the experiment that made the “agent as autonomous researcher” framing feel real rather than aspirational.
What I set up
I was running FEM simulations which required me running different experiments with variations in a certain variables and performing convergence studies. I extracted the relevant project context from my vault into a focused CLAUDE.md, copied it into the simulation workspace, opened it in VS Code with Claude Code, and gave the agent a narrowly scoped research goal: run these experiments with variations of mesh sizes, perform the postprocessing after the simulation is complete, and report which mesh size convergence is achieved.
What the agent did
It didn’t ask for a manual. It explored the environment — ran CLI commands to understand the filesystem, figured out how the FEM software was configured on that specific environment, identified available modules, created the required input files and post-processing scripts, submitted the jobs, and waited for results before continuing.
This wasn’t autocomplete. It looked much more like a junior researcher handed a project brief who figured out the environment themselves.
A few caveats worth being honest about: I had to guide it when it got stuck going in the wrong direction — that still happens. And building the FEM model from scratch remains out of reach for now. That requires the model to understand meshing, assembly, solver configuration — niche enough that the general-purpose foundation models aren’t trained on enough of it. Major FEM software companies are working on this (SimScale, for example, is going in this direction), and giving models the documentation of FEM software as context helps, but it’s not the same as having it encoded in the weights. That’s coming — just not yet.
Why the verification loop matters
The agent running the workflow is only half the picture. What keeps it useful rather than dangerous is the human verification step at the output.
The agent can automate simulation setup, job submission and monitoring, post-processing and plotting. What it can’t do is check whether the results are physically meaningful. That stays with the researcher. Agent handles execution; researcher handles physical interpretation and decides what’s worth studying next.
This maps directly onto the evaluator bottleneck from the deep research systems above. In a materials simulation context, the evaluator isn’t an automated benchmark — it’s physical intuition and domain knowledge. That doesn’t go away. It gets more important, at least for now.
As models get better at these niche scientific domains, multimodality and computer use, even that gap is expected to close. But we’re not there yet.
What this means for computational research
The question shifts from “can LLMs answer questions?” to something more interesting:
How should we design research workflows when competent agents can execute meaningful chunks of science?
Practically: think about constrained autonomy (narrow tool access beats broad), rich context files (a well-maintained vault is leverage), verification checkpoints (where does a human check before the agent continues), and traceability (can you reconstruct what the agent did and why).
Karpathy’s autoresearch repo is a useful design reference here — tiny codebase, one constrained edit surface, fixed experiment budgets, consistent evaluation metric. Everything the agent can touch is visible and bounded. That pattern transfers directly to simulation workflows even though the domain is completely different.
The thread running through both examples
The LLM-wiki and the HPC simulation look different on the surface, but they share the same structure:
- A well-scoped task the agent can decompose into tool calls
- Rich context provided upfront — project knowledge, schema, prior notes
- Tool access to the actual work environment
- A human verification layer at the output
Remove any of those four and the agent degrades — either producing low-quality outputs or running confidently in the wrong direction.
The broader lesson from the AI lab architectures is the same: the model is not the whole story. The infrastructure around it — the connectivity, the context, the evaluation layer — is what determines whether it’s actually useful.
Where this goes
Already here for early adopters: literature triage, first-pass synthesis, simulation setup and post-processing automation.
Emerging over the next year or two: semi-autonomous project agents that run multi-day investigations with human checkpoints, lab-aware agents that understand the specific cluster, software stack, and project conventions from a maintained context file.
The most honest description of where we are right now: meaningful chunks of research execution can be automated when the goal is well-specified, the context is rich, the tools are accessible, and the human stays in the validation loop. That’s already a significant shift. It’s not AGI. It’s a better division of labour.